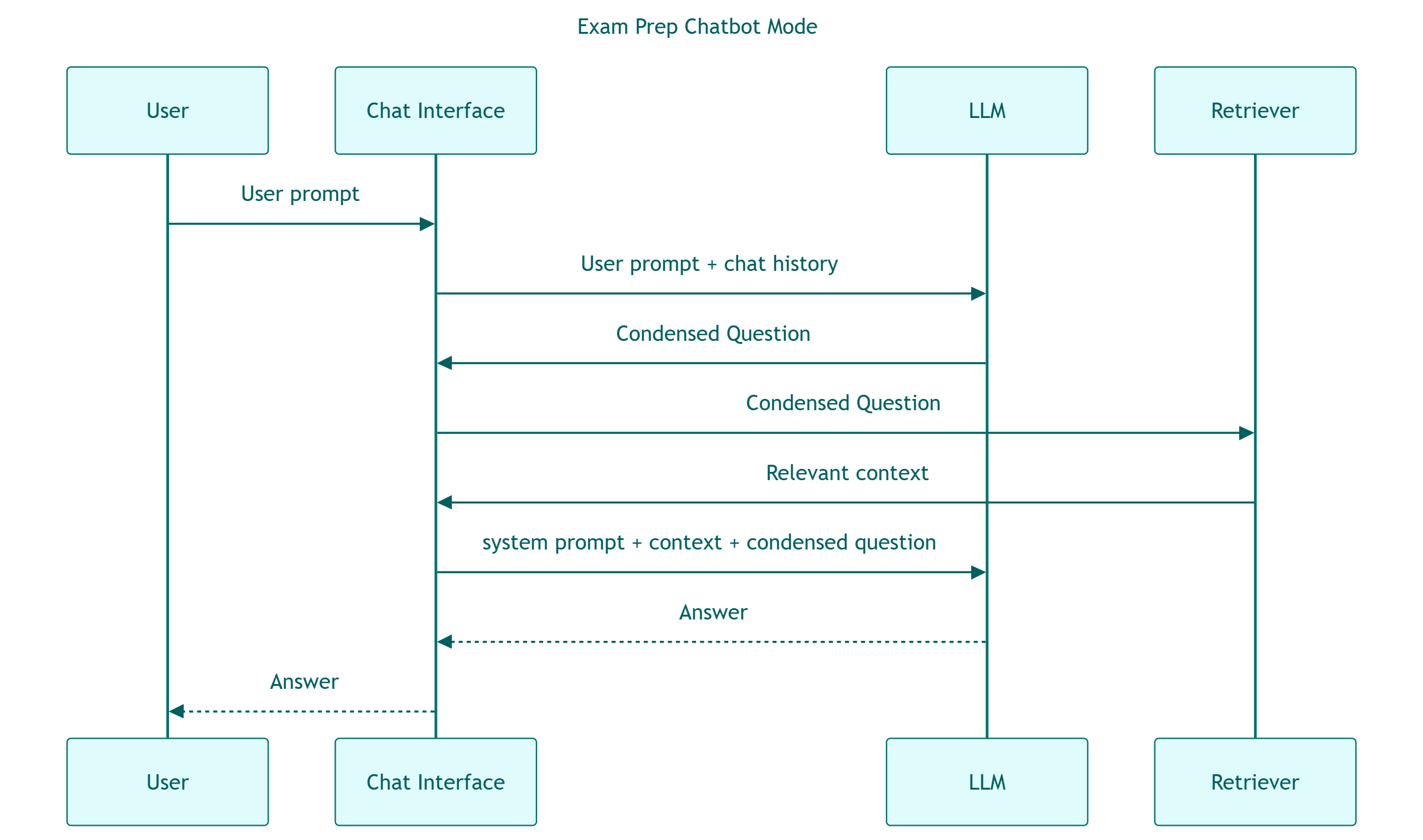
How can you quickly check your changes to your AI system are not breaking something else? What model should you use for inference when your provider tells you the model you’ve been using will no longer be available? Want to try a new chunking strategy for your RAG, but how to know if anything was improved at all?
These questions cannot be answered with the help of traditional automation testing in which test results are deterministic and you have a clear pass or fail criteria. AI-powered applications are non-deterministic by nature and evaluating them becomes more nuanced than just clicking some buttons and doing some assertions.
To help answer these questions, I spent 6 weeks building an automated evaluation system and used it against my RAG Chatbot for real-world practice: https://github.com/eliaspardo/rag-chatbot
The Evaluation System
My initial requirements were as simple as I needed a framework that allowed me to evaluate the application across the three dimensions I defined in my manual evals: Grounding (faithful to retrieved context), Completeness (contains expected elements), and Reasoning (relevant to question).
With time these requirements grew, but eventually I built a fully fledged evaluation framework consisting of:
Deepeval with some custom CLI options for parallel execution and selective runs, which allowed for quickly running specific evals after small tweaks.
MLflow to track results, app and eval parameters, plus a side-by-side comparison UI for systematic analysis.
Decoupled inference and eval models and added support for TogetherAI and Ollama. This allows you to use cheaper models in production for affordable and quick responses, while using more powerful models for evals, as the task is more nuanced and requires higher accuracy. It also enables you to easily swap out inference models for experimentation.
Test definition as code: tracking and versioning of eval metric definition and golden sample. These become your test data which is critical in case we want an audit trail or go back and revisit a specific configuration.
For me, the real game changer was the side-by-side comparison page, as it allowed me to see the impact of any given change at a glance, saving tons of time going back and forth looking at individual evals from different runs.
There was a lot I learned in the process, so would like to share the main takeaways.
The Main Takeaways
Failure Modes can have different sources
The app fails: these are the kinds of failures you expect and what you write evals for. Think of all the ways the application could misbehave, and on top of that, some specifics to AI applications like ungrounded correctness: when the app responds correctly but for the wrong reasons (e.g. pretrained knowledge vs retrieved context), hallucinations…
Combined failures: when both the app and the eval fail, these are the hardest to catch. A specific example:
The eval prompt: “I found an issue that the developers cannot fix in this sprint, should I open a defect report?”
Expected answer: “Yes, it’s recommended to create a defect report if the defect cannot be fixed in the same iteration.”
Actual answer: “Yes, you should open a defect report for the issue as it cannot be resolved within the same sprint and it blocks other current sprint activities.”
Human review: the problematic part is the hallucination “it blocks other current sprint activities”. The app hallucinated and the reasoning metric did not catch it. These types of issues trigger a ticket for the app as well as the eval code.
Start with a limited number of evals
This allows you to start simple and work on the infrastructure and framework early, helping you define what parameters you want to track and what tools suit your needs. Starting small also reduces the work on the hardest part: metric definition.
Metric definition is trickier than it sounds
… and this is assuming you’re clear on your manual metrics.
There are so many implicit assumptions when a human grades that encoding those into a prompt is not straightforward, so make sure you spend enough time here. Also, do not aim for like for like results with your manual graded results: you should look at trends more than absolute numbers, or this becomes a never-ending task.
Do spot checks on automated vs human-graded evals from time to time to account for changes to the application or the evals and make sure results are still in sync.
Framework requirement gathering comes first
I took a very iterative approach which required lots of rework and re-running test runs. As an example: I built the side-by-side comparison page quite late in the process, which was a missed opportunity for improved overall velocity. Taking a moment to think about this early on will save time in the long run.
On a different note: different evaluation goals call for separate evaluation sets
I learned this the hard way when I tried grading a mathematical calculation using my “grounding” metric. In this particular eval, completeness and reasoning were always passing, but grounding always failed, as the context retrieved did not contain references to the specific numbers used. After giving it some thought, it was clear that all calculations are ungrounded (unless you use the examples in the source document) and these kinds of evals called for a separate evaluation suite, focused on numerical or mathematical accuracy.
Same goes for the type of testing you want to do. This framework is pretty agnostic to what you want to measure, but you might need additional tooling depending on what you want to test. E.g. if you’re testing for performance you will need to gather token count, cost calculation, response times… When testing agents you will likely need to modify the plumbing so that you’re covering output correctness, resolution path and overall efficiency.
Wrapping it up
Building an AI Evaluation framework is very different from building a traditional test automation framework, as the nature of the system is completely different and you’re constantly on the lookout to check if your tests still work.
With this evaluation framework when Together AI sends me an email saying they’re deprecating the LLM I’m using in two weeks time, I can quickly try a range of models in a matter of minutes and choose the best replacement based on actual eval scores.
If you want to build something yourself I would suggest starting small, spend time defining the metrics and finding out your requirements, and then work on building your fully fledged eval suite.
Also, checkout my repo if you want some inspiration: https://github.com/eliaspardo/rag-chatbot
]]>
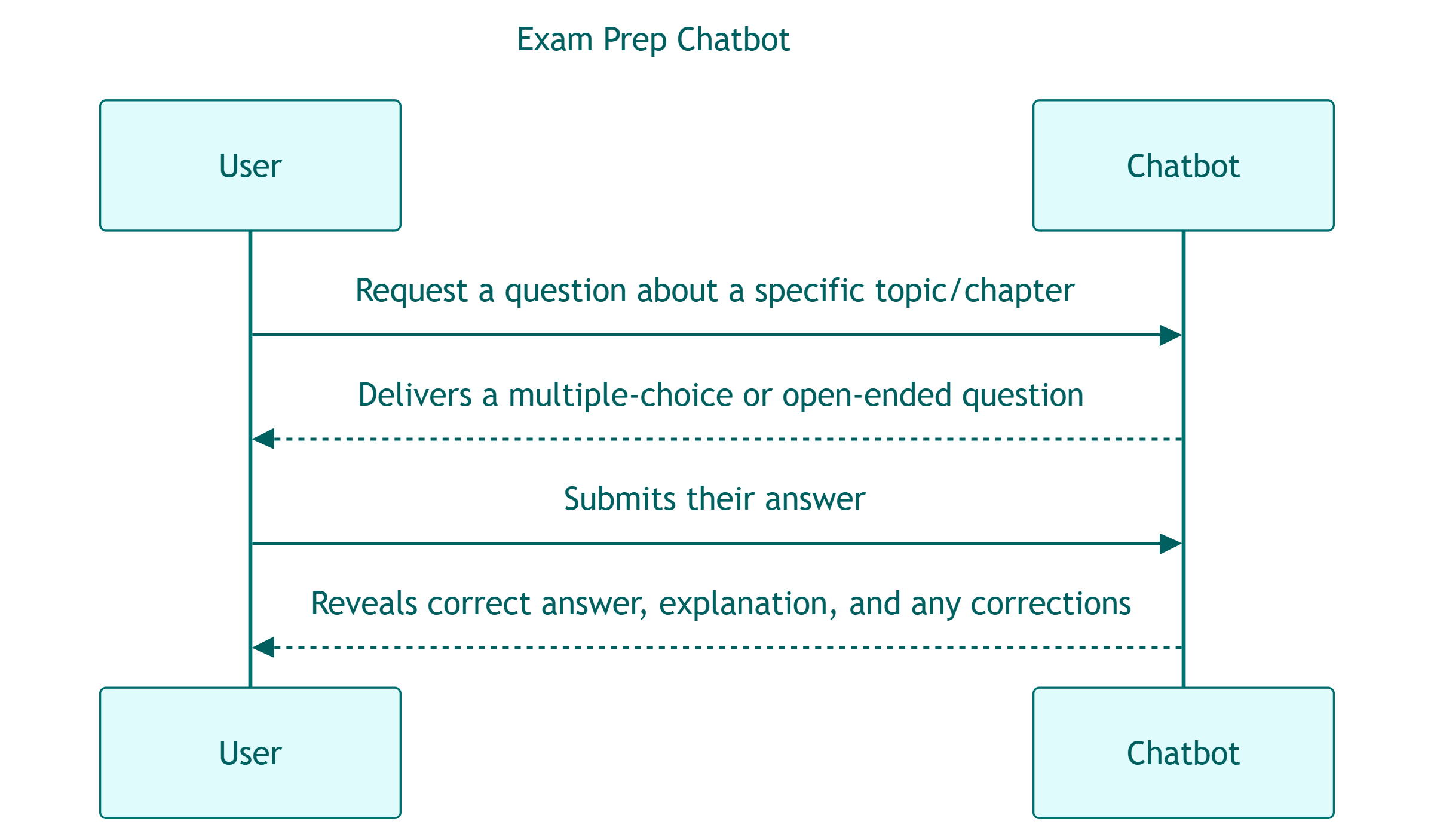
 While all this seems trivial for a human, it’s not so straightforward for an LLM: I’ve seen all sorts of erratic behaviors including the chatbot turning the user’s answer into a new question, or returning entire conversations back-to-back as a single response.
While all this seems trivial for a human, it’s not so straightforward for an LLM: I’ve seen all sorts of erratic behaviors including the chatbot turning the user’s answer into a new question, or returning entire conversations back-to-back as a single response.